| |
| |
|

Sven
Bader | Pour une Volltextsuche habe je cet Funktion geschrieben, avec Anpassungen funktioniert es aussi avec XLSX, PPTX, ODT, ODP, ODS et PAGES. on muss letztendlich qui Dossier entzippen et qui korrekte XML y identifier. chez XLSX ist es quelque chose verzweigter.
Profan Kompatibilität:
qui Unzip funktioniert ab X4, devant muss on sich une DLL pour chercher
Utf8_Decode allez ab X3, devant peux on sich quelque chose avec Translate$() zusammenbauen, cela zumindest häufige marque comment Umlaute ersetzt.
Proc ReadDocx
Paramètres inputFile$
Déclarer content$, filesize&, tempFile$, B#
tempFile$ = $TempDir + "docxopener" + "\\word\\document.xml"
'Entpacken
ifnot (FileExists(inputFile$))
Imprimer inputFile$;" pas trouvé!"
Retour
endif
UnZip inputFile$, ($TempDir + "docxopener") ,"word\document.xml"
filesize& = FileSize(tempFile$)
si (filesize& < 0)
Imprimer "Fehler beim Entpacken!"
Retour
endif
'Lesen
Faible B#, filesize& + 1
Assign #1, tempFile$
OpenRW #1
BlockRead(#1, B#, 0, filesize&)
Effacer #1
Fermer #1
content$ = String$(B#,0)
'joli faire
content$ = Utf8Decode(content$)
content$ = Translate$(content$,"<w:p","\n<w:p")'paragraphe Start DOCX
content$ = Translate$(content$,":p>",":p>\n\n")'paragraphe Ende
content$ = Translate$(content$,":tab/>",":tab/> ")'Tab
content$ = Translate$(content$,":br/>",":br/>\n")'Pause
content$ = Translate$(content$,":line-pause/>",":line-pause/>\n")'Pause
content$ = Translate$(content$," "," ")
Set("RegEx", 1)
content$ = Translate$(content$,"<[^>]*>",»)'Strip Tags
Set("RegEx", 0)
content$ = Trim$(content$)
Retour content$
ENDPROC
Cls
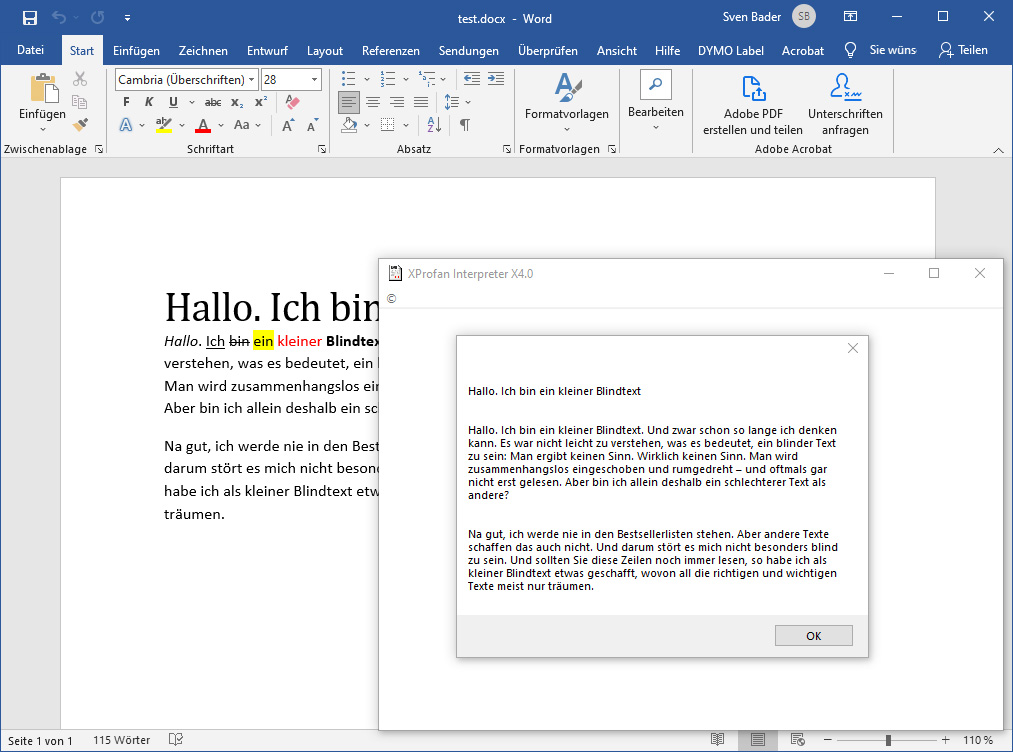
messagebox ReadDocx("test.docx") ,»,0
Waitinput
Fin
|
 |
| |
| |
| |
|
 (111)
(111)




 Deutsch
Deutsch English
English Français
Français Español
Español Italia
Italia{kind=link}