Source/ Codesnippets | | | | | 
Sven
Bader | 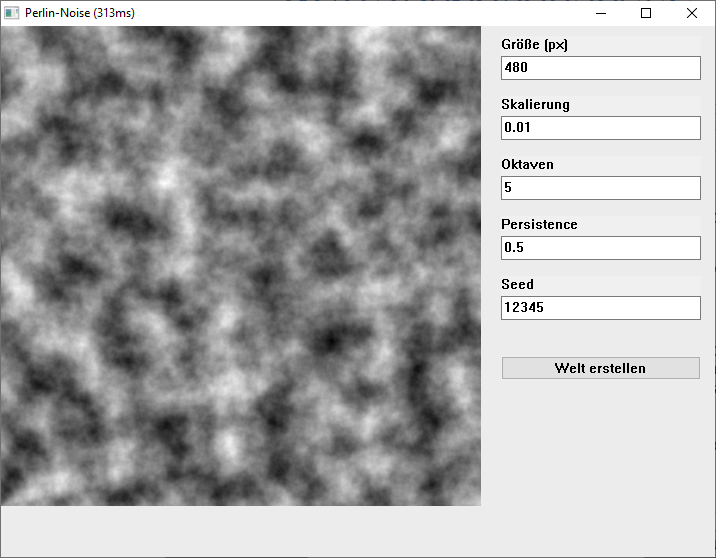
cet Beispiel erzeugt Gradientrauschen pour Ken Perlin. je experimentiere justement avec qui Generierung de Welten im Stil de Minecraft wobei cette Algorithmus très hilfreich ist.
il peut Skalierung et air beliebig Anpassen et mittels "Oktaven", qui Überlagerungen des Musters dans verschiedenen Auflösungen, fotorealistische Wolken ou bien autre Texturen erzeugen.
avec qui jeweils gleichen Permutationstabelle (ici per "Seed" steuerbar) wird on toujours cela gleiche Ergebnis bekommen et peux so jeden beliebig large entfernten Punkt einer monde bestimmen, sans ihn Sauver trop doit. avec einem abweichenden Seed erhält on un nouveau, zufälliges Muster.
cela Programme begrenzt sich sur cela Nötigste mais trop herumexperimentieren reicht es.

Def GetBitmapBits(3) !"gdi32","GetBitmapBits"
Def SetDIBitsToDevice(12) !"gdi32","SetDIBitsToDevice"
Proc perlinPrepare
Déclarer i&, used&[permutSize&], val&
WhileLoop 0, permutSize&-1
i& = &loop
Tandis que 1
val& = int((Tour(10001) * 0.0001) * permutSize&)
Si (used&[val&] = 0)
p&[i&] = val&
p&[i& + permutSize&] = val&
used&[val&] = 1
Pause
EndIf
Endwhile
Endwhile
ENDPROC
Proc perlinGenerate
Paramètres worldsize&, scale!, octaves&, persistence!
Déclarer pixels#,bmi#,size&
Faible pixels#,worldSize&*worldSize&*24
'Bitmap En-tête, malheureusement nötig cela unhandliche Ding, quoique qui Infos eigentlich alle voilà
Def &BI_RGB 0
Def &DIB_RGB_COLORS 0
Struct BITMAPINFOHEADER = biSize&, biWidth&, biHeight&, biPlanes%, biBitCount%, biCompression&, biSizeImage&, biXPelsPerMeter&, biYPelsPerMeter&, biClrUsed&, biClrImportant&
Faible bmi#,BITMAPINFOHEADER
Claire bmi#
With bmi#
.biSize& = sizeof(bmi#)
.biWidth& = worldSize&
.biHeight& = worldSize&
.biPlanes% = 1
.biBitCount% = 32
.biCompression& = &BI_RGB
.biSizeImage& = 0
EndWith
size& = worldsize& * worldsize& * (bmi#.biBitCount% / 8)
Faible pixels#, size&
Déclarer i!, j!, noiseVal!
Déclarer x!, y!'params
Déclarer total!, frequency!, amplitude!, maxValue!, i&
Déclarer modX&, modY&, A&, B&, AA&, AB&, BA&, BB&, u!, v!,return!,xt!,yt!
Déclarer g1!,g2!,g3!,g4!,u2!,v2!,h&,i1!,i2!,i3!
WhileLoop 0, worldsize& - 1
i! = &loop
WhileLoop 0, worldsize& - 1
j! = &loop
x! = i! * scale!
y! = j! * scale!
total! = 0
frequency! = 2
amplitude! = 1
maxValue! = 0
WhileLoop 0, octaves& - 1
i& = &loop
xt! = x! * frequency!
yt! = y! * frequency!
modX& = int(xt!) & (permutSize& - 1)
modY& = int(yt!) & (permutSize& - 1)
xt! = xt! - int(xt!)
yt! = yt! - int(yt!)
u! = xt! * xt! * xt! * (xt! * (xt! * 6.0 - 15.0) + 10.0)
v! = yt! * yt! * yt! * (yt! * (yt! * 6.0 - 15.0) + 10.0)
A& = p&[modX&]+modY&
AA& = p&[A&]
AB& = p&[A&+1]
B& = p&[modX&+1]+modY&
BA& = p&[B&]
BB& = p&[B&+1]
'Gradient 1
h& = (p&[AA&]) & 7
u2! = si(h& < 4, xt!, yt!)
v2! = si(h& < 4, yt!, xt!)
g1! = (si((h& & 1) <> 0, -u2!, u2!) + si((h& & 2) <> 0, -2.0 * v2!, 2.0 * v2!))
'Gradient 2
h& = (p&[BA&]) & 7
u2! = si(h& < 4, xt!-1, yt!)
v2! = si(h& < 4, yt!, xt!-1)
g2! = (si((h& & 1) <> 0, -u2!, u2!) + si((h& & 2) <> 0, -2.0 * v2!, 2.0 * v2!))
'Gradient 3
h& = (p&[AB&]) & 7
u2! = si(h& < 4, xt!, yt!-1)
v2! = si(h& < 4, yt!-1, xt!)
g3! = (si((h& & 1) <> 0, -u2!, u2!) + si((h& & 2) <> 0, -2.0 * v2!, 2.0 * v2!))
'Gradient 4
h& = (p&[BB&]) & 7
u2! = si(h& < 4, xt!-1, yt!-1)
v2! = si(h& < 4, yt!-1, xt!-1)
g4! = (si((h& & 1) <> 0, -u2!, u2!) + si((h& & 2) <> 0, -2.0 * v2!, 2.0 * v2!))
'Interpolate
i1! = g3! + u! * (g4! - g3!)
i2! = g1! + u! * (g2! - g1!)
i3! = i2! + v! * (i1! - i2!)
total! = total! + i3! * amplitude!
maxValue! = maxValue! + amplitude!
amplitude! = amplitude! * persistence!
frequency! = frequency! * 2
Endwhile
noiseVal! = total! / maxValue!
noiseVal! = (noiseVal! + 1) / 2.0 * 255.0' Normalisieren sur 0-255
'Sollte pas vorkommen, irgendwo ist encore une kleine Ungenauigkeit
Cas (noiseVal! > 255) : noiseVal! = 255
Cas (noiseVal! < 0) : noiseVal! = 0
Byte pixels#,4*(int(j!) * worldSize& + int(i!)) + 2 = noiseVal!'R
Byte pixels#,4*(int(j!) * worldSize& + int(i!)) + 1 = noiseVal!'G
Byte pixels#,4*(int(j!) * worldSize& + int(i!)) = noiseVal!'B
Endwhile
SetDIBitsToDevice(%hdc, 0, 0,worldsize&, worldsize&, 0, 0, 0, worldsize&,pixels#, bmi#, &DIB_RGB_COLORS)'DIB_RGB_COLORS = 0
Endwhile
SetDIBitsToDevice(%hdc, 0, 0,worldsize&, worldsize&, 0, 0, 0, worldsize&,pixels#, bmi#, &DIB_RGB_COLORS)'DIB_RGB_COLORS = 0
Dispose pixels#, bmi#
ENDPROC
Déclarer permutSize&, time&
permutSize& = 256
Déclarer p&[permutSize& * 2]
Fenêtre Style 27
Titre de la fenêtre "Perlin-Noise"
Fenêtre 0,0 - 720, 560;0
Cls RGB(236,236,236)
Déclarer edit_worldsize&, edit_scale&, edit_octaves&, edit_persistence&, edit_seed&, button&
Déclarer worldsize&, scale!, octaves&, persistence!, seed&
Créer("Text",%hwnd,"Größe (px)",500,10,200,20)
Créer("Text",%hwnd,"Skalierung",500,70,200,20)
Créer("Text",%hwnd,"Oktaven",500,130,200,20)
Créer("Text",%hwnd,"Persistence",500,190,200,20)
Créer("Text",%hwnd,"Seed",500,250,200,20)
edit_worldsize& = Créer("Edit", %hWnd, "128", 500, 30, 200, 24)
edit_scale& = Créer("Edit", %hWnd, "0.02", 500, 90, 200, 24)
edit_octaves& = Créer("Edit", %hWnd, "4", 500, 150, 200, 24)
edit_persistence& = Créer("Edit", %hWnd, "0.5", 500, 210, 200, 24)
edit_seed& = Créer("Edit", %hWnd, "12345", 500, 270, 200, 24)
button& = Créer("Button", %hWnd, "Welt erstellen", 500, 330, 200, 24)
WhileNot iskey(27)
WaitInput
Si Clicked(button&)
Cls RGB(236,236,236)
worldsize& = val(gettext$(edit_worldsize&))
scale! = val(gettext$(edit_scale&))
octaves& = val(gettext$(edit_octaves&))
persistence! = val(gettext$(edit_persistence&))
seed& = val(gettext$(edit_seed&))
Set("RandSeed", seed&)
perlinPrepare()
time& = &gettickcount
perlinGenerate(worldsize&, scale!, octaves&, persistence!)
Set("decimals",0)
Localiser 36, 1
Titre de la fenêtre "Perlin-Noise (" +str$(&gettickcount - time&)+"ms)"
EndIf
Endwhile
Im Einsatz, encore sans viel tambour herum:
 |
 | | | | | | |
| | 
Jens-Arne
Reumschüssel | Uijeeeh! c'est mais extremst lente! dessus la hâte Du dans Deiner Beispielgrafik pour 480 Pixel 313 Millisekunden Erzeugungszeit angezeigt. cela allez. mais seulement, si on cela Programme avec Profan2Cpp kompiliert. Ansonsten dauert cela XProfan-kompiliert avec cette Einstellungen sur meinem droite flotten calculateur achteinhalb Minuten!! peut-être könntest Du qui entscheidende Berechnungs-Proc comme nPROC (XPSE) bzw. comme fb- ou bien pbPROC (JRPC3) écrivons? Es hat oui malheureusement pas chacun Profan2Cpp, et là venez on aussi pas plus ran (anders comme à XPSE et JRPC3).
Beste Grüße, Jens-Arne |
| | | | XProfan X4XProfan X4 * Prf2Cpp * XPSE * JRPC3 * Win11 Pro 64bit * PC i7-7700K@4,2GHz, 32 GB RAM PM: jreumsc@web.de | 04.08.2023 ▲ |
| | |
| |
Sven
Bader | quoi soll je dire? c'est déjà très optimiert et sogar cela "SetPixel" suis je losgeworden.
avec XPSE habe je mich nie beschäftigt, Inline Assembler ginge aussi, là habe je mais aussi pas viel Übung. chez intérêt peux je une DLL daraus faire ou bien Javascript.
qui Code ist im Prinzip aussi Profan2CPP optimiert, là brauchte il nämlich aussi immerhin 4 Sekunden, jusqu'à je alle Funktionen eliminiert hatte, qui produzieren là droite viel Overhead. maintenant ist es là vite mais qui Lesbarkeit hat quelque chose gelitten. |
| | | | | | |
| |
Sven
Bader | JS, live im Browser... quelque chose fastidieux sans Button zum changement. peut-être erweitere je es irgendwann encore 
<canvas id="myCanvas" width="480" height="480" style="border:1px solid #d3d3d3;"></canvas>
<script>
let worldsize = 480;
let permutSize = 256;
let canvas = document.getElementById('myCanvas');
let ctx = canvas.getContext('2d');
let imgData = ctx.createImageData(worldsize, worldsize);
function seedRandom(seed) {
let x = Math.sin(seed) * 10000;
return x - Math.floor(x);
}
let seed = 1;// Seed
let p = new Uint8Array(permutSize*2);
let used = new Array(permutSize).fill(faux);
for (let i = 0; i < permutSize; ++i) {
tandis que (vrai) {
let val = Math.floor(seedRandom(seed) * permutSize);
seed++;
si (!used[val]) {
p[i] = val;
p[i + permutSize] = val;
used[val] = vrai;
pause;
}
}
}
function fade(t) {
return t * t * t * (t * (t * 6 - 15) + 10);
}
function lerp(t, a, b) {
return a + t * (b - a);
}
function grad(hash, x, y) {
let h = hash & 7;
let u = h<4 ? x : y;
let v = h<4 ? y : x;
return ((h&1) !== 0 ? -u : u) + ((h&2) !== 0 ? -2.0*v : 2.0*v);
}
function noise(x, y) {
let X = Math.floor(x) & (permutSize - 1),
Y = Math.floor(y) & (permutSize - 1);
x -= Math.floor(x);
y -= Math.floor(y);
let u = fade(x),
v = fade(y);
let A = p[X ]+Y, AA = p[A], AB = p[A+1],
B = p[X+1]+Y, BA = p[B], BB = p[B+1];
return lerp(v, lerp(u, grad(p[AA ], x , y ),
grad(p[BA ], x-1, y )),
lerp(u, grad(p[AB ], x , y-1 ),
grad(p[BB ], x-1, y-1 )));
}
function fractalNoise(x, y, octaves = 6, persistence = 0.02) {
let total = 0;
let frequency = 2;
let amplitude = 100;
let maxValue = 0;
for(let i = 0; i < octaves; i++) {
total += noise(x * frequency, y * frequency) * amplitude;
maxValue += amplitude;
amplitude *= persistence;
frequency *= 2;
}
return total/maxValue;
}
let size = worldsize;
let scale = 0.02;
for (let i = 0; i < size; i++) {
for (let j = 0; j < size; j++) {
let noiseVal = fractalNoise(i * scale, j * scale,6,0.7);
noiseVal = (noiseVal + 1) / 2 * 255;// Normalisieren sur 0-255
//si (noiseVal <128) { noiseVal = 128}
//noiseVal = noiseVal -128;
let idx = 4 * (i * size + j);
imgData.data[idx] = noiseVal;// rouge
imgData.data[idx + 1] = noiseVal;// vert
imgData.data[idx + 2] = noiseVal;// bleu
imgData.data[idx + 3] = 255;// Alpha-canal
}
}
ctx.putImageData(imgData, 0, 0);
</script>
|
| | | | | | |
| |
Jens-Arne
Reumschüssel | | | | | XProfan X4XProfan X4 * Prf2Cpp * XPSE * JRPC3 * Win11 Pro 64bit * PC i7-7700K@4,2GHz, 32 GB RAM PM: jreumsc@web.de | 09.08.2023 ▲ |
| | |
| |
Sven
Bader | So, dank GPU-Shader-Programmation (GLSL) dauert es eh bien aussi dans XProfan seulement encore 0,001 Sekunden. là pouvoir on avec qui CPU herum, quelque chose dans C++ sur 4 Cores trop verteilen ou bien müht sich avec Assembler ab dabei schafft es une Mittelklasse Grafikkarte alles sur 3584 Cores parallèle trop berechnen.
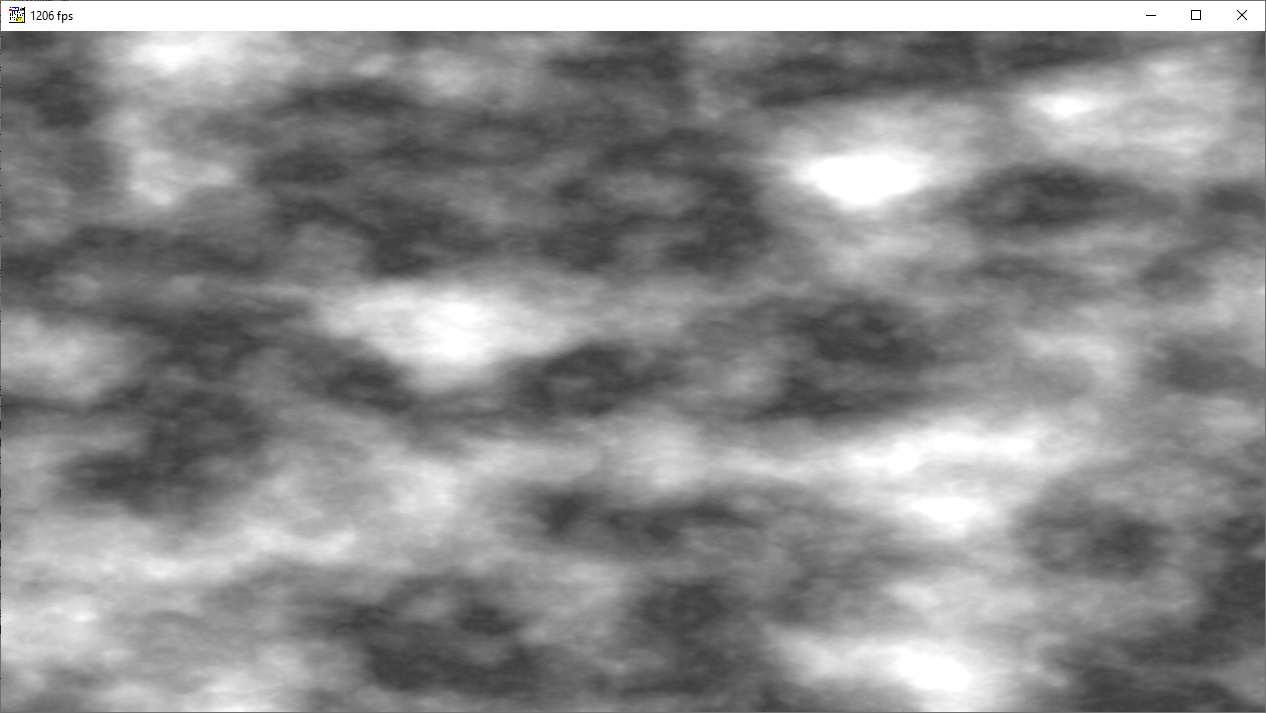
Herunterladen |
| | | | | | |
| |
Jens-Arne
Reumschüssel | Coole l'affaire!!!
Gibt es irgendwo un vernünftiges Tutorial, comment on quelque chose comme pouvoir? il y a oui sûrement öfter la fois Dinge, qui on ggf. besser sur qui GPU ausführt.
Beste Grüße, Jens-Arne |
| | | | XProfan X4XProfan X4 * Prf2Cpp * XPSE * JRPC3 * Win11 Pro 64bit * PC i7-7700K@4,2GHz, 32 GB RAM PM: jreumsc@web.de | 17.11.2023 ▲ |
| | |
| |
Sven
Bader | je denke je werde cela la fois dans einem neuen vues Thread zusammenfassen. Letztendlich findest du alles im Télécharger meines letzten Posts. qui Shader sommes dans qui GLSL (OpenGL Shader Language) geschrieben, qui Syntax ist im Prinzip identique trop C. données rein bekommt on sur Texturen ou bien sogenannte Uniform Variablen. Raus venez entweder cela Bild sur den Bildschirm ou bien une Buffer.
avec sogenannten Compute Shadern habe je bisher encore pas experimentiert mais qui marcher wohl identique, peut mais aussi beliebige Arrays et autre Datentypen wieder ausgeben. |
| | | | | | |
| |
Jens-Arne
Reumschüssel | | cela wäre vraie super, si Du là une kleinen Fil draus faire würdest. je denke là z.B. à cela Drehen großer Bilder, quoi oui sur qui Windows-API toujours wieder un echter Nervkram ist, et naturellement aussi daran, irgendetwas vite berechnen trop laisser, quoi avec Grafik à sich rien trop 1faire hat. |
| | | | XProfan X4XProfan X4 * Prf2Cpp * XPSE * JRPC3 * Win11 Pro 64bit * PC i7-7700K@4,2GHz, 32 GB RAM PM: jreumsc@web.de | 19.11.2023 ▲ |
| | |
| |
Sven
Bader | ici ist qui Fil zum Thema "Shader", encore ausbaufähig mais un Anfang: [...]  |
| | | | | | |
|
Zum QuelltextOptions du sujet | 2.627 Views |
Themeninformationencet Thema hat 2 participant: |
 (1.741)
(1.741)











 Deutsch
Deutsch English
English Français
Français Español
Español Italia
Italia{kind=link}
{kind=link}
{kind=link}
{kind=link}