| |
| |
|

Sven
Bader | Für eine Volltextsuche habe ich diese Funktion geschrieben, mit Anpassungen funktioniert es auch mit XLSX, PPTX, ODT, ODP, ODS und PAGES. Man muss letztendlich die File entzippen und die korrekte XML darin identifizieren. Bei XLSX ist es etwas verzweigter.
Profan Kompatibilität:
Die Unzip funktioniert ab X4, davor muss man sich eine DLL dafür suchen
Utf8_Decode geht ab X3, davor kann man sich etwas mit Translate$() zusammenbauen, das zumindest häufige Zeichen wie Umlaute ersetzt.
Proc ReadDocx
Parameters inputFile$
Declare content$, filesize&, tempFile$, B#
tempFile$ = $TempDir + "docxopener" + "\\word\\document.xml"
'Entpacken
ifnot (FileExists(inputFile$))
Print inputFile$;" nicht gefunden!"
Return
endif
UnZip inputFile$, ($TempDir + "docxopener") ,"word\document.xml"
filesize& = FileSize(tempFile$)
if (filesize& < 0)
Print "Fehler beim Entpacken!"
Return
endif
'Lesen
Dim B#, filesize& + 1
Assign #1, tempFile$
OpenRW #1
BlockRead(#1, B#, 0, filesize&)
Erase #1
Close #1
content$ = String$(B#,0)
'Schön machen
content$ = Utf8Decode(content$)
content$ = Translate$(content$,"<w:p","\n<w:p")'Paragraph Start DOCX
content$ = Translate$(content$,":p>",":p>\n\n")'Paragraph Ende
content$ = Translate$(content$,":tab/>",":tab/> ")'Tab
content$ = Translate$(content$,":br/>",":br/>\n")'Break
content$ = Translate$(content$,":line-break/>",":line-break/>\n")'Break
content$ = Translate$(content$," "," ")
Set("RegEx", 1)
content$ = Translate$(content$,"<[^>]*>","")'Strip Tags
Set("RegEx", 0)
content$ = Trim$(content$)
Return content$
EndProc
Cls
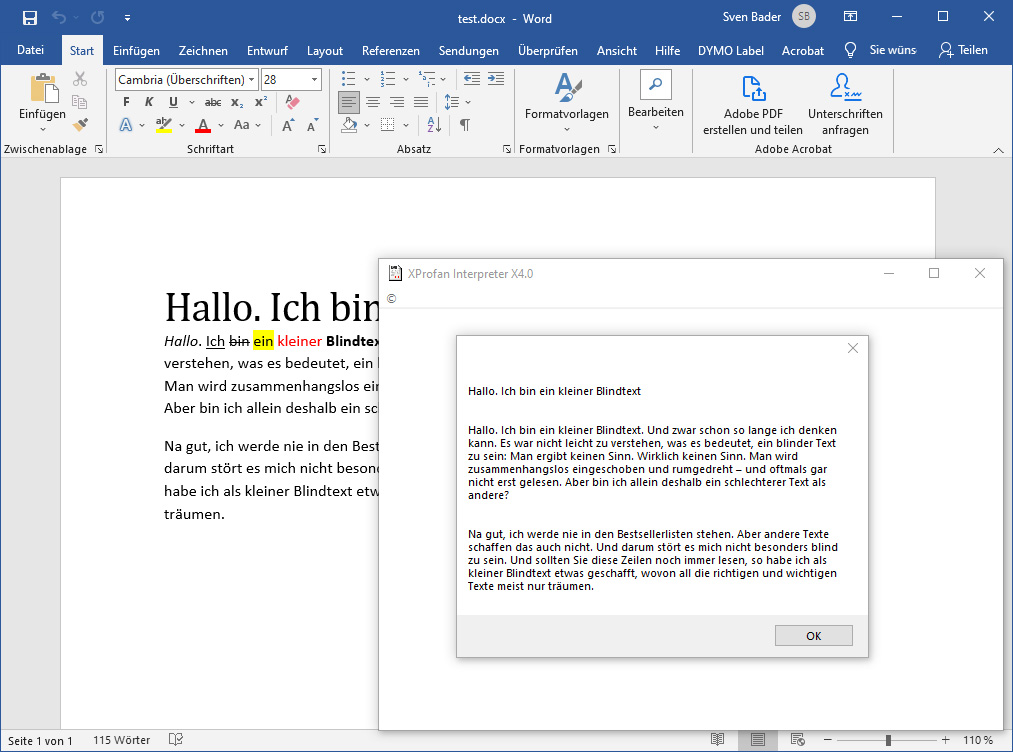
messagebox ReadDocx("test.docx") ,"",0
Waitinput
End
|
 |
| |
| |
| |
|
 (376)
(376)




 Deutsch
Deutsch English
English Français
Français Español
Español Italia
Italia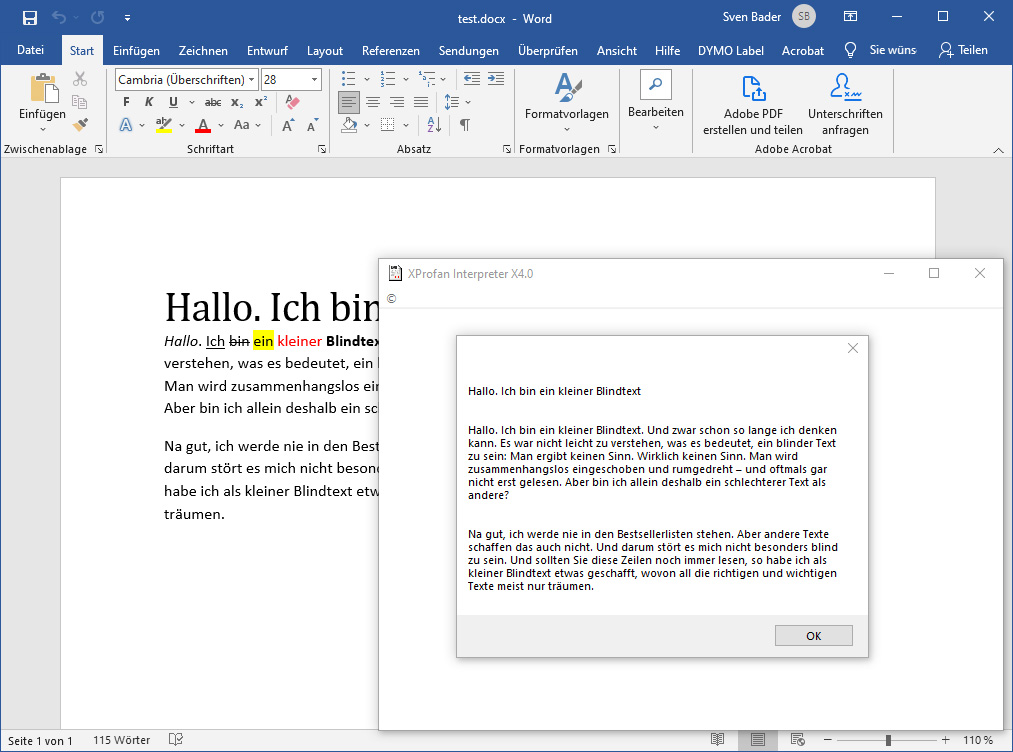{kind=link}